Photo by Denys Nevozhai on Unsplash
Hello, everyone! It has been a long time. As the pandemic got into full swing last year, my bandwidth for cognitive tasks took a big hit and some things fell by the wayside, such as this blog. I did not intend to ghost y'all like that; alas, here we are. Perhaps I'll write more on that another time, for now, let's jump into something that I was recently tackling1.
What is Dependabot?
Dependabot is a handy tool now owned and incorporated into GitHub that monitors your repositories dependencies and updates them, a chore that many maintainers can find laborious. It is not the only tool available to perform this task, but it is the one that many will use if they are already on GitHub since it is easy to setup and manage.
When Dependabot identifies a package you use that can be updated (based on your semver rule in package.json, for example), or it knows of a security issue in a package you use or referenced by a package you use, Dependabot can create a PR (pull request) to update that package. It is pretty smart and will only ever have one PR per package, so if multiple releases occur, it will close out any pending PR for that package and make a new one. It is a really handy tool with a variety of configuration options; I'm not going to delve into those here – you can read about them in the official documentation.
When Dependabot was in preview, it would create the PR, wait for all relevant checks to have been performed – such as your CI (continuous integration) processes like linting and testing, and then on success of these checks, auto-merge the change into the branch you configured it to target. However, this is a security issue, especially if you also have CD (continuous deployment) set up as a malicious package could be published, causing Dependabot to trigger a new deployment, which could then propagate that malicious package to all your package users, and their users, etc. Quite rightly, the decision was made to take that feature out of Dependabot and leave it to each individual use-case to decide what to do with the PRs created by Dependabot. However, this then led to a new problem – managing the PRs.
To avoid security issues in your releases, make sure that there is a manual QA (quality assurance) step somewhere between any automated update and an actual release of the updated code.
Dependabot has the ability to limit how many open PRs it creates, which is helpful, but they still require manual intervention. If you have rules like "every PR needs at least X reviewers", then it can quickly become a chore almost as annoying as the one it tries to address.
So what to do? Auto-merge is a potential security issue, not auto-merging is a time sap.
Do not enable auto-merging on a branch used for CD. It really is a bad idea and a big security risk. Packages do get hacked sometimes and tidying up after a malicious publish is not easy. To avoid security issues in your releases, make sure that there is a manual QA (quality assurance) step somewhere between any automated update and an actual release of the updated code. For example, you could do this by having Dependabot operate on a branch that is a copy of the CD branch and then have a process for merging the Dependabot updates across to your main branch before a release.
💡Check out CodeQL, another GitHub feature, if you want to add some automated vulnerability checking to your repository
For the remainder of this entry, we will assume that you are using Dependabot on a main branch that is not continuously deployed. However, just as with licensing, it is ultimately your responsibility to make sure the code you release, including its dependencies do not introduce vulnerabilities, so make sure to consider your specific scenario before enabling things like Dependabot and auto-merging of the changes it makes.
What are GitHub Actions?
GitHub Actions are GitHub's approach to supporting the kinds of tasks that have traditionally been performed by CI and CD platforms like Travis, CircleCI, and Jenkins. Using a combination of YAML configurations and scripts referred to as actions, you can build workflows that perform all kinds of automated processes from running tests to managing your GitHub repository issues. They are incredibly powerful (and therefore, should be used responsibly).
Many first and third-party actions exist to help you build your workflows. I have used actions to run tests across multiple platforms, update code coverage stats in CodeCov, and, most recently, help manage Dependabot PRs. In addition, GitHub Actions have access to the incredibly powerful gh CLI tool.
💡Checkout the documentation on GitHub Actions regarding security hardening to learn how to use GitHub Actions more securely.
GitHub Actions are free for public repositories, see the GitHub Actions documentation for more information, including pricing for private repository usage.
Setting Things Up
1. Your GitHub Repository Settings
Before you setup the merging workflow, you need to make a few changes to your GitHub repository.
Auto-merge

First, go to your repository Settings tab and under the Options section, ensure that Allow auto-merge is checked. This does not make every PR auto-merge, but it does allow for specific PRs to be set to auto-merge – this will be important.
Status Checks
If you don't have status checks enabled for your repository, then it means that a PR can just be merged without any reviews or code quality checks occurring. I highly recommend setting status checks as it ensures at least some level of code quality assurance before your code or anyone else's is merged.
For the purposes of this discussion, it is assumed that you have set your repository to require at least one review per PR before it can be merged, and at least one non-instant code quality check (such as a test run, or lint check).
Status checks are mandated for PRs to specific branches by using Branch Protection Rules. These are configured in your repositories Settings under Branches. In the following screenshot, the main branch – the default branch, has branch protection rules applied. Branch protection rules can be applied to specific branches, or a range of branches by using a selector like feature/*.
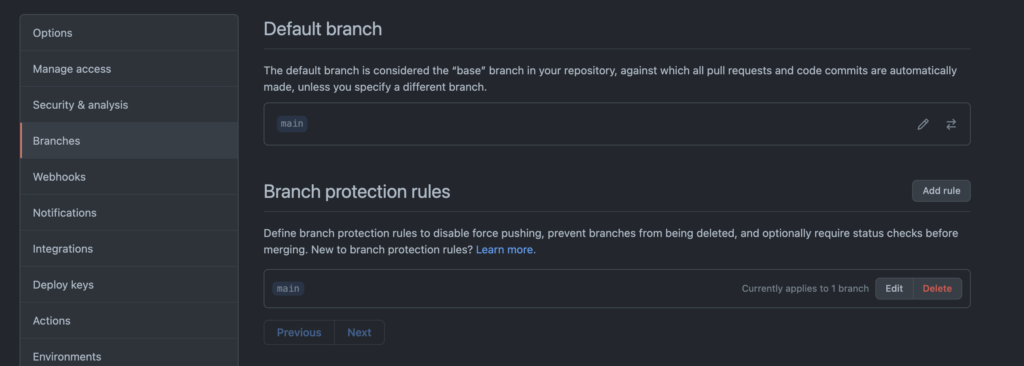
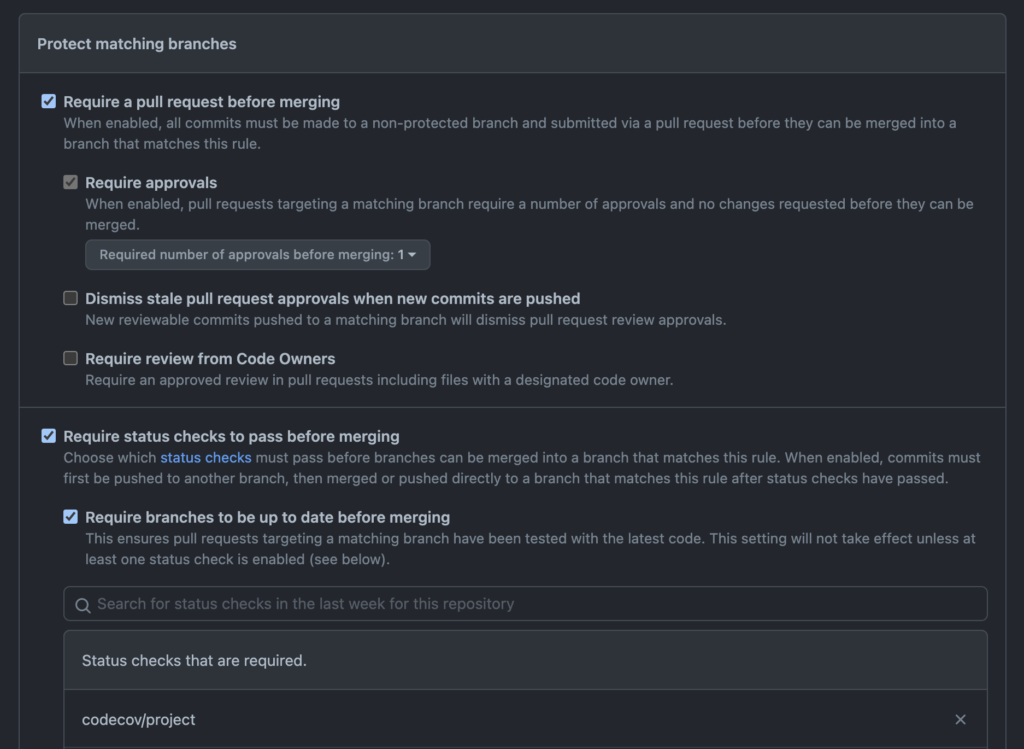
main default branchIf you add rules for a branch (or set of branches) or edit an existing rule, you can specify all sorts of measures to control when code is suitable for merging in the branches that match that rule. In the following screen, the rule has been configured such that code can only be merged when:
- It comes from a PR
- It has at least one approving reviewer
- It is up-to-date with the target branch
- The
codecov/projectstatus check has passed
Why at least one non-instant quality check?
The auto-merge setting for GitHub PRs is only useful for PRs that are not already passing all status checks. I do not know if this is still the case, but at one time it was the case that the command we are going to use to tell GitHub to auto-merge the PR would fail if the PR is already in a mergeable state. If you want to auto-merge PRs that are already mergeable when our new workflow runs, you will need to call a different command. This is left as an exercise for the reader.
2. Dependabot
You will need to enable Dependabot on your repository. Follow GitHub instructions to set it up how you want it. This blog assumes defaults, but you should be able to make it work with other configurations.
3. GitHub Actions
With Dependabot in place (and probably creating PRs for you already) and your status checks running, we can now setup our automation.
There are two things we need our automation to do.
- We need it to approve the PR as we have mandated that we need at least 1 reviewer in order for code to be allowed to merge.
- We need to enable auto-merge for the PR so that it will merge once our status checks are completed.
To add a GitHub Actions workflow, all you need to do is add a YAML file describing the workflow to the .github/workflows folder of your repository. Each YAML file describes a specific workflow, including what triggers the workflow, what permissions it has, and the jobs that it performs. Triggers can be specific events in your repository (such as creating a PR or raising an issue), webhooks, on a specific schedule such as once a week, or even via events fired from another workflow.
Let's take a look at the workflow for our approve and auto-merge workflow, and then we can discuss some of the important pieces. Since this isn't a deep dive into GitHub Actions, I will skim over some of the details to get to the pertinent info.
name: Dependabot Pull Request Approve and Merge
on: pull_request_target
permissions:
pull-requests: write
contents: write
jobs:
dependabot:
runs-on: ubuntu-latest
# Checking the actor will prevent your Action run failing on non-Dependabot
# PRs but also ensures that it only does work for Dependabot PRs.
if: ${{ github.actor == 'dependabot[bot]' }}
steps:
# This first step will fail if there's no metadata and so the approval
# will not occur.
- name: Dependabot metadata
id: dependabot-metadata
uses: dependabot/fetch-metadata@v1.1.1
with:
github-token: "${{ secrets.GITHUB_TOKEN }}"
# Here the PR gets approved.
- name: Approve a PR
run: gh pr review --approve "$PR_URL"
env:
PR_URL: ${{ github.event.pull_request.html_url }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
# Finally, this sets the PR to allow auto-merging for patch and minor
# updates if all checks pass
- name: Enable auto-merge for Dependabot PRs
if: ${{ steps.dependabot-metadata.outputs.update-type != 'version-update:semver-major' }}
run: gh pr merge --auto --squash "$PR_URL"
env:
PR_URL: ${{ github.event.pull_request.html_url }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
There is a bit to unpack there, so let's go over it.
name: Dependabot Pull Request Approve and Merge
First, we have the name of the workflow, which is "Dependabot Pull Request Approve and Merge". This will be shown in the GitHub user interface when referring to your workflow.
on: pull_request_target
Next, we have the triggers. In this case, we have just one trigger; pull_request_target. This trigger should rarely be used and, when it is used, used with care as it provides a read/write access token. We need this as it allows us to perform tasks to update our PR. There are specific types of each trigger if you need to narrow down exactly when your workflow occurs; pull_request_target defaults to opened, reopened, and synchronize, which means our workflow will trigger when a PR is opened, updated, or reopened. For more information on this trigger and its types, see the GitHub documentation, also check out this blog on security implications of misusing this trigger.
permissions: pull-requests: write contents: write
After specifying the trigger for the workflow, we specify the scope of permissions we are granting the workflow. Every workflow has a secret available, GITHUB_TOKEN, which is used to authenticate the actions that the workflow wants to perform. Each trigger type has a restricted level of permissions, and while we cannot elevate permissions outside of those restrictions, we can control the scope of permissions allowed within the restrictions.
In our case, we need write access to the pull requests so that we can modify the PR itself, and we need write access to the repository contents because we need to be able to request merging. Even though setting a PR to auto-merge may seem like we are just editing the PR, because it results in the code getting merged, we have to make sure we have permission to do that future merge too.
jobs:
dependabot:
runs-on: ubuntu-latest
# Checking the actor will prevent your Action run failing on non-Dependabot
# PRs but also ensures that it only does work for Dependabot PRs.
if: ${{ github.actor == 'dependabot[bot]' }}
steps:
# This first step will fail if there's no metadata and so the approval
# will not occur.
- name: Dependabot metadata
id: dependabot-metadata
uses: dependabot/fetch-metadata@v1.1.1
with:
github-token: "${{ secrets.GITHUB_TOKEN }}"
# Here the PR gets approved.
- name: Approve a PR
run: gh pr review --approve "$PR_URL"
env:
PR_URL: ${{ github.event.pull_request.html_url }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
# Finally, this sets the PR to allow auto-merging for patch and minor
# updates if all checks pass
- name: Enable auto-merge for Dependabot PRs
if: ${{ steps.dependabot-metadata.outputs.update-type != 'version-update:semver-major' }}
run: gh pr merge --auto --squash "$PR_URL"
env:
PR_URL: ${{ github.event.pull_request.html_url }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
At the end of the file, we have the jobs themselves. In this case, we have a single job named dependabot. This job runs on an instance of the latest Ubuntu image, as specified by runs-on: ubuntu-latest. GitHub Actions support a range of operating systems and versions, and you can even configure a job to run on a matrix of these things, but we do not need that fanciness – the Ubuntu images tend to be the cheapest and the fastest, so we that is what we are using.
We control when the job runs with a condition, if: ${{ github.actor == 'dependabot[bot]' }}. This means that if the PR was created by some entity other than dependabot[bot], we won't do anything, preventing us from auto-approving other folks code contributions.
Finally, we describe the steps in the job. In this case there are three steps:
name: Dependabot metadata
This step uses an action from Dependabot that gets us information about the update.name: Approve a PR
This step performs the review approval. We do this using the awesomeghCLI.name: Enable auto-merge for Dependabot PRs
This step sets the PR to auto-merge using a squash merge strategy. You could change this strategy to whatever you prefer – possibly omitting it if you want the repository default to be used.
Versions
You may have noticed that the last step in our job has a condition:
if: ${{ steps.dependabot-metadata.outputs.update-type != 'version-update:semver-major' }}This is why we have the "Dependabot metadata" step. In this condition, we use that metadata to ensure that we only allow auto-merging of minor and patch level updates. After all, a major version change is likely a breaking a change, and we don't want to automatically include those, even if they do pass our status checks. So, this condition ensures that we leave major updates as open PRs for manual verification before merging.
If you decided not to merge these PRs, you can tell Dependabot exactly how to handle this dependency in future, even preventing it suggesting major updates to that package again.
Conclusion
This was a long post, but hopefully a useful one. I want to acknowledge that I did not come up with this all on my own. My strategy here was built from the excellent GitHub documentation that also goes into detail about workflows and Dependabot.
Thanks for reading. If you have feedback or questions, don't forget to leave a comment.
It's nice to be back. 🙂
- Don't worry, I haven't forgotten about our series on React server-side rendering – I'll get back into that soon [↩]