BrowserStack has been an incredibly useful resource for tracking down bugs and testing fixes when I am working on websites. This often requires accessing locally deployed sites or sites accessible over a VPN connection, and to do that, BrowserStack needs some local code running to be able to route the traffic accordingly.
 Up until recently, my browser of choice has been Google Chrome, for which BrowserStack provides a handy extension to add support for local sites. However, since the Windows Creators Update, I have been giving Microsoft Edge a shot1 and no such extension exists. Instead, BrowserStack provides a download, BrowserStackLocal.exe , and a secret with which to run it. This works great, but there are a couple of annoyances.
Up until recently, my browser of choice has been Google Chrome, for which BrowserStack provides a handy extension to add support for local sites. However, since the Windows Creators Update, I have been giving Microsoft Edge a shot1 and no such extension exists. Instead, BrowserStack provides a download, BrowserStackLocal.exe , and a secret with which to run it. This works great, but there are a couple of annoyances.
- I have to remember to run it.
- It is a blocking process.
There are a variety of ways this problem can be solved. I decided to take the opportunity to expand my PowerShell fu and put together some cmdlets to run the BrowserStackLocal process in the background. Specifically, I wanted to compare PowerShell jobs with plain old processes for this specific purpose.
First: Jobs
Since the running the command is a blocking operation, I decided to try wrapping it in a PowerShell job so that it would sit in the background. This is useful since the job gets terminated when the PowerShell session ends, which makes it less likely for me to forget. The downside is that each PowerShell session could have its own job, but only the one that started BrowserStackLocal will actually end it, but I was certain I could work with that.
Getting started
The first cmdlet for starting BrowserStackLocal is cunningly named Start-BrowserStackLocal , shown here:
function Start-BrowserStackLocal()
{
$browserStackSecret = "<YOUR-SECRET-HERE>"
$browserStackLocalDir = "F:\Program Files (x86)\BrowserStackLocal"
$bslocal = Get-Command "$browserStackLocalDir\BrowserStackLocal.exe" -ErrorAction SilentlyContinue
$job = Get-Job BrowserStackLocal -ErrorAction SilentlyContinue
if ($job) {
Write-Host "BrowserStackLocal already started: " -ForegroundColor Yellow -NoNewline
Write-Host "$($job.ID):$($job.Name)" -ForegroundColor Cyan
return
}
if (-Not $bslocal) { throw "Cannot find BrowserStackLocal" }
Write-Host "Starting BrowserStackLocal..." -ForegroundColor Yellow
$job = Start-Job -Name BrowserStackLocal -ScriptBlock {
try {
Push-Location $using:browserStackLocalDir
& $using:bslocal.Path $using:browserStackSecret
}
finally {
Pop-Location
}
}
if2
{
Write-Host (Receive-Job $job)
Remove-Job $job
} else {
Write-Host "Started " -NoNewline -ForegroundColor Yellow
Write-Host "$($job.ID):$($job.Name)" -ForegroundColor Cyan
}
}
This has basic room for improvement, like having the secret and the path be parameters to the cmdlet, or environment variables; I happened to stop tinkering once it worked for me, so feel free to expand on it.
At the start, we check to see if we already have a job for BrowserStackLocal since we only need one. If we do not, then we get on with making sure BrowserStackLocal can be found where we expect it. If everything looks good, then the job gets started.
To tackle the chance that my script may fail due to the BrowserStackLocal command either getting an incorrect key or discovering it is already running, I added a Wait-Job call. The nice thing here is that since normally BrowserStackLocal blocks, we can assume that if the job did not reach a completion state, then the executable command is running. I take advantage of that fact, so if the Wait-Job returns, we can assume things went wrong and dump the details of the problem back to the console.
Stopping the job
Once the job is running, we need to be able to terminate it.
function Stop-BrowserStackLocal()
{
$job = Get-Job BrowserStackLocal -ErrorAction SilentlyContinue
if (-Not $job) {
return
}
Write-Host "Stopping BrowserStackLocal: " -ForegroundColor Yellow -NoNewline
Write-Host "$($job.ID):$($job.Name)" -ForegroundColor Cyan -NoNewline
Write-Host "..." -ForegroundColor Yellow
Stop-Job $job
Remove-Job $job
}
This is a much simpler cmdlet than the one to start the job. It has two main tasks:
- See if the job is actually running
- If it is, stop it
I added some helpful output so we could see it working and that was that.

Problems with jobs
This solution using jobs works great but it is not ideal. Each PowerShell session has its own jobs, so you have to know which session actually started BrowserStackLocal in order to stop it. Not only that, but if PowerShell did not start it at all, you cannot stop it from there with these commands at all. Jobs are great but they are not really the right tool for this…er…job.
Second: Processes
The wise man would have probably started here. I did not because I wanted to learn about jobs. Now that I have, I am wiser and so, I thought I would recreate my success but this time using the Xxx-Process cmdlets of PowerShell.
Getting started again
Using processes, the start cmdlet looks like this:
function Start-BrowserStackLocal()
{
$browserStackSecret = "<YOUR-SECRET-HERE>"
$browserStackLocalDir = "F:\Program Files (x86)\BrowserStackLocal"
$processes = Get-Process BrowserStackLocal -ErrorAction SilentlyContinue
if ($processes) {
Write-Host "BrowserStackLocal already started: " -ForegroundColor Yellow
foreach ($process in $processes) {
Write-Host " $($process.ID): $($process.Name)" -ForegroundColor Cyan
}
return
}
$bslocal = Get-Command "$browserStackLocalDir\BrowserStackLocal.exe" -ErrorAction SilentlyContinue
if (-Not $bslocal) { throw "Cannot find BrowserStackLocal" }
Write-Host "Starting BrowserStackLocal..." -ForegroundColor Yellow
Start-Process -FilePath $bslocal.Path -WorkingDirectory $browserStackLocalDir -ArgumentList @($browserStackSecret) -WindowStyle Hidden
Wait-Process -Name BrowserStackLocal -Timeout 3 -ErrorAction SilentlyContinue
$processes = Get-Process BrowserStackLocal -ErrorAction SilentlyContinue
if ($processes)
{
foreach ($process in $processes) {
Write-Host " $($process.ID): $($process.Name)" -ForegroundColor Cyan
}
}
}
Since the BrowserStackLocal executable starts more than one process, I added some loops to output information about those processes. Now if we try to start the command and it is already running, we will get the same feedback, regardless of where the command was started.
Stopping the process
Switching to processes makes the stop code a little more complicated, but only because I wanted to provide some additional detail (we could have just called Stop-Process BrowserStackLocal and it would stop all matching processes).
function Stop-BrowserStackLocal()
{
$processes = Get-Process BrowserStackLocal -ErrorAction SilentlyContinue
if (-Not $processes) {
Write-Host "BrowserStackLocal is not running"
return
}
Write-Host "Stopping BrowserStackLocal..." -ForegroundColor Yellow
foreach ($process in $processes) {
Write-Host " $($process.ID): $($process.Name)" -ForegroundColor Cyan
Stop-Process $process
}
}
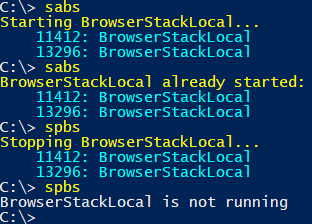
Helpful aliases
Finally, to make the task of starting and stopping a little less arduous, I added some aliases (inspired by the helpful sasv and spsv aliases of Start-Service and Stop-Service).
Set-Alias sabs Start-BrowserStackLocal Set-Alias spbs Stop-BrowserStackLocal
Conclusion
TL;DR: Use processes to start processes in the background3.
The rest
I am pretty pleased with how this little PowerShell project worked out. I get to keep using Microsoft Edge with minimal effort beyond what I had when using Google Chrome for my BrowserStack testing, enabling me to take advantage of the performance and battery-life improvements Edge has over Chrome. Not only that, but I got to learn some new things about PowerShell.
- You don't get closures entirely for free in PowerShell. I suspected this, but I learned the hard way. However…
- We can pass local variables into script blocks using the $using:<variable> syntax instead of passing an argument list and adding parameters to our script.
- Debugging jobs can be a pain until you learn the value of Receive-Job for getting error information.
- Use Wait-Job with a little time out to give your job chance to fail so that you can spit out some error information.
- You have to stop a job before you can remove it.
- Don't use jobs to control background processes; use processes instead
I have not gone so far yet as to start the BrowserStackLocal service automatically, but I can see value in doing so, especially if I did a lot of BrowserStack testing on local sites every day (of course, I'd probably want to redirect the output to $null in that scenario rather than see feedback on the running processes with every shell I opened).
What are your thoughts? Do you use PowerShell jobs? Do you use BrowserStack? Will you make use of these cmdlets? Fire off in the comments.