A week or two ago I discovered that my blog was not loading and I had no idea why it was throwing the 500 error code nor for how long it had been doing so. Having experienced this once or twice before, I went into my administration dashboard, stopped the website and application pool, then started them again. This fixed the immediate issue and my blog was back online, but I was not satisfied. I no longer wanted to discover this issue by chance so I went looking for ways to monitor my site.
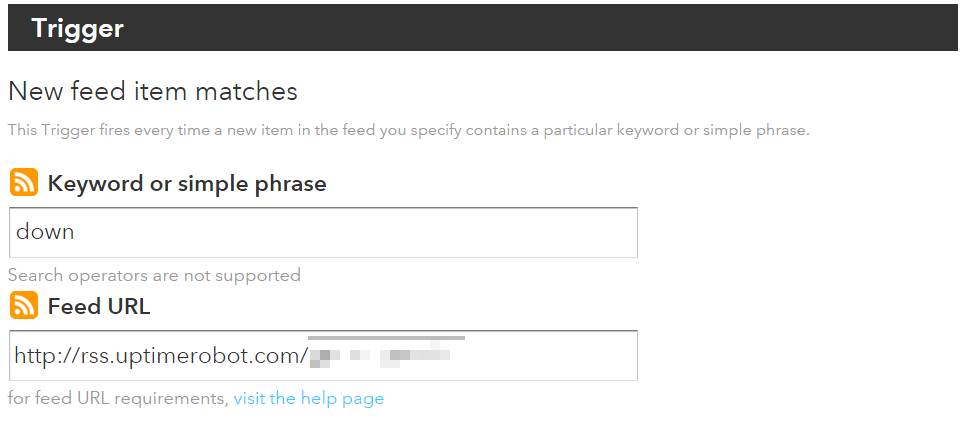
I found several methods that could help, including one that uses my site's RSS feed as an IF trigger on IFTTT1, but I did not like this approach, so I looked around a little more. Eventually, after reading over a few options, I settled on using Uptime Robot. Uptime Robot allows up to 30 monitors on their free tier, which can be monitored at various frequencies down to every five minutes (if you want more monitors that are checked more frequently, you can look at their various paid options). Using this service, I not only will find out if my site goes down, but I also get stats over time on the reliability of my site.
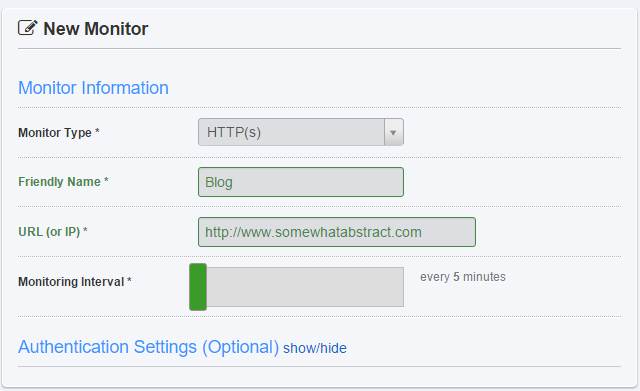
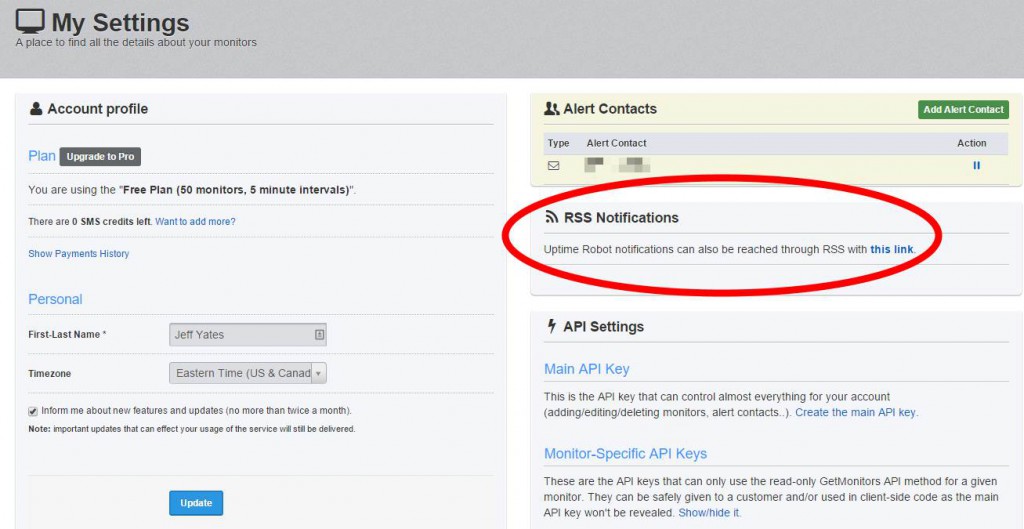
Setting up a monitor was really easy and a quick test resulted in an email telling me the site was down, followed by another telling me it was back up once the site was restored. This was great although I felt an email was not enough. While Uptime Robot provides SMS support for sending alerts, they also provide you with an RSS feed on your account that syndicates your uptime alerts. Using an IF rule and the IF app on my phone, I was able to set up phone notifications for when my blog transitioned state between being up and down.
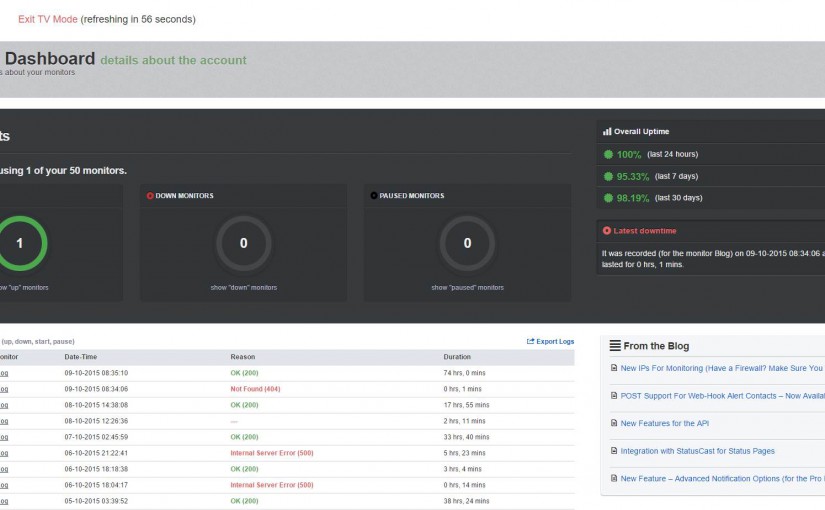
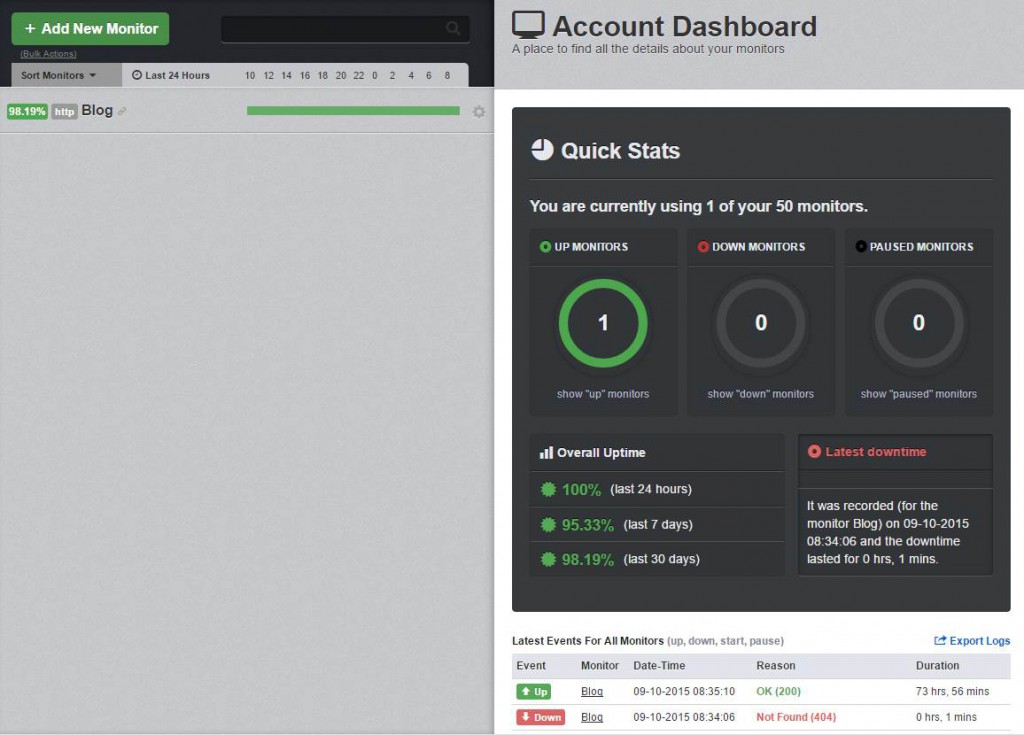
I retested the monitor (this meant taking the site down and waiting until the next monitor cycle) and convinced myself that the IF trigger and action were working satisfactorily. Now, whenever my blog experiences a glitch, I will know within about five minutes or so. Not only that, but if it fixes itself before I get chance to do so, I will have some stats that I can use to determine if there is a fundamental issue with my site's up-time. Uptime Robot provides a dashboard for managing monitors and viewing stats.
There is also a "TV Mode" for showing live stats, should you want a more permanent display in your office, for example. All of these views have a responsive layout, making it easy to check statuses from a mobile device.
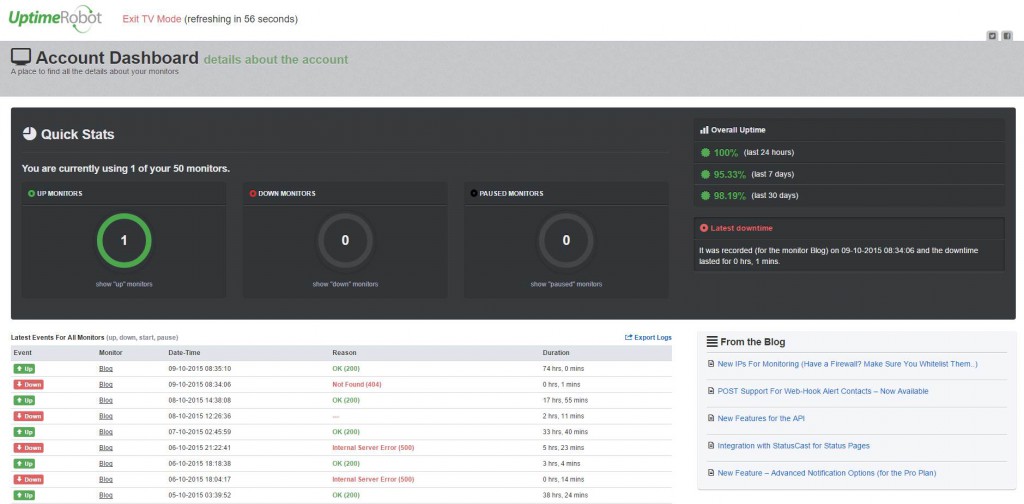
Since setting the monitor up, my site has been down a lot. I do not know for sure if this is more or less than usual because I was not monitoring it this closely before, but I learned that my hosting provider has been updating servers recently. These hardware changes have caused all sorts of havoc with the reliability of site up-time for a lot of people, it seems2. Thankfully, due to both Uptime Robot and the responsiveness of my hosting providers support team, most issues were discovered and resolved in a reasonable time.
During these availability issues, I learned that just finding out when my site is down was not sufficient, so I added an additional "site back up" rule to IFTTT. This turns out to be really useful when your site is down while one is sleeping as it removes the need to go check if it the site is back up upon waking.
In Conclusion
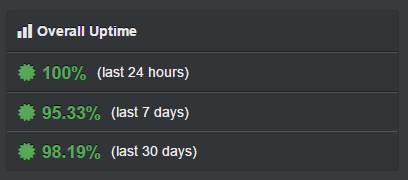
While I am disappointed that my site was down, I was really happy to see that my Uptime Robot monitoring was doing exactly what I wanted. Not only that, but I have screen grab showing less than perfect stats, which makes for a great addition to this blog.
Uptime Robot is a nice discovery and a welcome addition to my suite of tools. The inclusion of a RSS feed to check monitor status as well as an API, which I am yet to explore, make it easy to integrate the information from Uptime Robot monitors into other tools.