Photo by Nikola Knezevic on Unsplash
This is part 11 of my series on server-side rendering (SSR):
- 🤷🏻♂️ What is server-side rendering (SSR)?
- ✨ Creating A React App
- 🎨 Architecting a privacy-aware render server
- 🏗 Creating An Express Server
- 🖥 Our first server-side render
- 🖍 Combining React Client and Render Server for SSR
- ⚡️ Static Router, Static Assets, Serving A Server-side Rendered Site
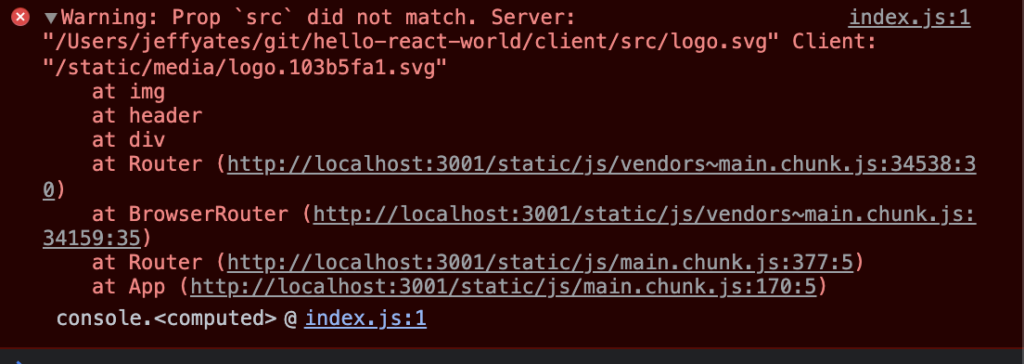
- 💧 Hydration and Server-side Rendering
- 🦟 Debugging and fixing hydration issues
- 🛑 React Hydration Error Indicator
- [You are here] 🧑🏾🎨 Render Gateway: A Multi-use Render Server
Way back in January 2020, I started blogging about server-side rendering (SSR) React. I intended it to be a short, four post series that would go into the details of what SSR is, how to do it, and the pitfalls that lie within.
This is post eleven of the four post series, and perhaps the last (at least for now). Over the course of the last ten posts, we have created a simple React app that server-side renders and successfully hydrates. Along the way, we have learned about the complexities of server-side rendering and hydration, and from this we can identify some important lessons.
- The initial render of client and server renders must be the same for hydration to be successful
- Maintaining a server-side rendering solution can become complex, especially as the app itself becomes more complex (and it doesn't help that React only reports hydration problems in its development build until React 18)
- Reasoning about an app to ensure we consider both the server-side and client-side behavior can be a pain
We cannot change the first point. In order for the hydration to be successful, we need our initial render to be the same on both client and server. To achieve this, we need to understand how our code will render in both contexts. However, with some clever components (and hooks, in some cases), we can simplify things to reduce the impact of the other two points. There are frameworks available such as NextJS that provide these features for us. However, I find great value in understanding the complexities of something to grasp exactly what tradeoffs third-party solutions are incurring, and at the time I was working on the SSR solution for Khan Academy, moving to NextJS was far too great a lift. So, in this series we have rolled our own solution.
First, by using components like WithSSRPlaceholder in Wonder Blocks Core, we abstract away the general complexity of understanding the process of server-side rendering to ensure our result hydrates properly.
Second, by testing our code in development in diverse browser environments we can check for things that often cause hydration errors (such as browser feature detection being used to change what gets rendered – remember, the server has no idea what the user has configured in their browser, what their screen size is, etc.).
Finally, by changing the server-side rendering solution from one that knows lots about our frontend code to one that knows as little as possible, we can build a server-side rendering approach that will work without needing to be redeployed every time we change our frontend. And that is where we are heading in this post as we created such a server to perform server-side rendering at Khan Academy.
Goliath and the Render Gateway
For more than two years, the Khan Academy backend that underpins our website and mobile apps has been undergoing a major re-architecture. We named this massive project, Goliath – part pun on the new backend language we had chosen, Go, and part pun on the absolutely colossal amount of work we had ahead of us to get the job done. You can read all about it in these posts on the Khan Academy Engineering blog:
- Go + Services = One Goliath Project
- Half a million lines of Go
- Technical choices behind a successful rewrite project
- Beating the odds: Khan Academy’s successful monolith→services rewrite
The re-architecture was a big project, made ever more complex by the need to keep the site running smoothly for the millions of folks that rely on us as we transitioned things off the old architecture and on to the new, piece by piece1. As part of this re-architecture, we knew we needed to change the way our website was served and so I, along with the amazing team I work with, were tasked with creating a server that would render our web pages. We made a variety of decisions to simplify the work and to simplify maintenance long term:
- We would only support rendering pages that used our latest frontend architecture
Supporting legacy tech-debt laden code would only perpetuate problems and would most definitely increase the complexity and volume of work to be done. By using our current frontend architecture, all the information about the site, including what page to render for which routes, would be codified within the frontend code. - We would get it working first and get it working fast second
While we made decisions all the way through to avoid performance issues, we also deliberately avoided making any performance optimizations before we knew what a working solution looked like. And we took measurements – always take measurements before and after when you are making performance improvements. - We would make it generic enough to cope with the multiple changes we make to our frontend each day. We deploy many times in one day to fix bugs and release new features. Our engineers work hard to make these deployments invisible to users and we wanted to implement a solution that would support that effectively.
Our strategy was to get something working, move eligible routes over to that something one by one, and make incremental changes as we went to improve performance and fix bugs.
We knew up front that we would be using an edge cloud platform like Fastly to route the traffic and ultimately provide caching for our SSR'd pages, so we made sure that our design incorporated support for things like the Vary response header to support efficient caching (though we did not use that to begin with, no premature optimization). We went as far as including code in our frontend that could track what request headers were used by a page rendering so that we could build that Vary header with a view to utilizing it once we were at a stage where cache optimization made sense2.
After a little back-and-forth we settled on a name for this new approach to rendering our website; the Render Gateway.
What we did
We spent quite some time building the main Render Gateway code, solving many problems like:
- How do we know what code to run?
- How do we build a result that the cloud edge service can understand?
- What does that result look like?
Many test implementations were stood up as we added more features, including the ability to:
- Verify incoming requests so that we can immediately throw away spam
- Add different status values and headers to the response to support redirects
- Track request header access and add proper support for the
Varyheader - Log and trace requests in sufficient detail to debug issues in production
By mid-2020 we had a working server and we went live, serving the logged-out homepage and more from this new service. It worked!
It was also slow and had a massive memory leak. 😢
And so began the arduous work of performance testing and memory investigations as we worked to improve things. Our biggest performance wins came from reducing the amount and size of the JavaScript that it takes to render our site (an ongoing and effective focus for site performance in general) and from utilizing the Vary header along with our cloud edge service to reduce the amount of traffic the server needs to handle. For example, we do not gain much value from rendering pages that are for logged-in users so our cloud edge does not ask us to SSR those pages. In addition, better use of the Vary header increases our cache hit rate, leading to more logged-out users benefitting from SSR'd pages.
The Memory Leak
Sadly, the memory leak was a real pain. Every 20 to 40 production requests, an instance would hit a soft or hard memory limit and die. Google App Engine (GAE) works admirably in the face of an unstable app. It will detect the soft or hard memory limit violation, kill the service and spin up new instances as needed, even resubmitting the failed request so that the caller only sees the impact as a slower request rather than a complete failure. This meant that we could keep our leaky implementation serving production users while we investigated the problem, allowing us to continue supporting the Goliath project, albeit with a bit of a limp.
Myself and John Resig spent many hours performing memory investigations, writing multi-process render environments and more in our attempts to both track down and mitigate the memory leak. Just when we thought we had noticed what was holding onto memory, we would realise we were wrong and seek a new path. This was only exacerbated by how hard it was to generate the leak in development, especially since the Chrome dev tools used to investigate memory issues would hold onto references of the code it loaded, and our main usage of memory was that very code that we loaded dynamically. It was weeks of effort until another colleague noted a similar leak in another node service that we had in production. It turned out that the @google-cloud/debug-agent package we were using has a problem and it appears to be down to the very same v8 engine issue we encountered when using Chrome dev tools to investigate the memory issue. Once we removed that dependency, the memory leak went away and instead of crashing every 20-40 requests, each instance of the Render Gateway can handle millions of requests without a care3.
How it works
At its core, the Render Gateway is a generic express server written in JavaScript to operate in Node on Google App Engine. It takes a URL request and renders a result using a configured render environment. Because it uses an API to define that render environment, it is incredibly versatile. There are no rules to what that render environment does other than take in a request and provide a response. Here's an example from the publicly available repository4:
const {runServer} = require("../../src/gateway/index.js");
async function main() {
const renderEnvironment = {
render: (
url /*: string*/,
renderAPI /*: RenderAPI*/,
) /*: Promise<RenderResult>*/ =>
Promise.resolve({
body: `You asked us to render ${url}`,
status: 200,
headers: {},
}),
};
runServer({
name: "DEV_LOCAL",
port: 8080,
host: "127.0.0.1",
renderEnvironment,
});
}
main().catch((err) => {
console.error(`Error caught from main setup: ${err}`);
});
If you were to run this code with node, you would get a server listening on port 8080 of your local machine with support for the following routes:
/_api/ping
This will returnpong, and provides a way to test if the server is responsive./_api/version
This will return the value of theGAE_VERSIONenvironment variable, something that Google App Engine sets which you can configure at deployment to specify the version of the server code being run./_ah/warmup
Google App Engine supports a warmup handler that it sometimes runs to warm up new instances of an app when scaling. By default, this just returnsOK, but the app can be configured to do additional work as needed./_render
This performs the actual render. The URL to be rendered is specified using aurlquery param.
If you invoked http://localhost:8080/_render?url=http://example.com with this server running, it would respond with a 200 status code and the text You asked us to render http://example.com.
The magic is the render environment, which in this case is a very simple object with a single render function:
const renderEnvironment = {
render: (
url /*: string*/,
renderAPI /*: RenderAPI*/,
) /*: Promise<RenderResult>*/ =>
Promise.resolve({
body: `You asked us to render ${url}`,
status: 200,
headers: {},
}),
};
The Render Gateway source also includes an environment implementation that uses JSDOM, allowing you to construct a more complex environment. However, it does nothing specifically related to React because how your code actually renders server-side is up to you and how you configure it. In fact, because it is built on express, you can plug-and-play the various pieces used to build the main startGateway call to implement your own approach if you so desire, even if you don't want to use Google App Engine.
At Khan Academy, we have a custom render environment that uses some organizational conventions and custom header values populated by our cloud edge service to identify which version of our frontend code is needed. The render environment then downloads (or retrieves from cache) that code and executes it within an isolated node environment to produce the body, status, and response headers (including the aforementioned Vary header) for the result. This is then sent in response to the caller. All the code executed to actually produce a result is from the downloaded code at the time of the request. To support this, we have some conventions, components, and frameworks that allow developers to access request header values, set response header values, and update the response status code from within our frontend code in a manner that feels natural (for example, a <Redirect/> component abstracts away the work of setting the status code and the Location header as needed). This means that our engineers, when working on our frontend code, do not need to context switch between thinking about client-side rendering and server-side rendering; instead, they have idioms to hand that enable them to build frontend user experiences that just work.
Our simple app revisited
Now to come full circle, we can envisage what our server-side rendering solution might look like using the Render Gateway. Instead of importing the client-side code at build time, we could leverage a render environment using JSDOM to dynamically load the code when a request is made, decoupling our server from our client.
I have made some changes to demonstrate this concept of using a manifest. However, this change still assumes a client build local to the server. If we wanted to make this entirely client-build agnostic, we would change our render environment to download the files (including the manifest) from a CDN instead. The GAE_VERSION environment value, or some header we receive could indicate the version of our frontend we need. We can then look up a manifest in our CDN to tell us the URLs of files we need, download them, execute them, and invoke the rendering process to get a result.
For now, if we are in production, we look for ../client/build/ folder to load the manifest and then load the files from that same folder; in development, we defer to the client webpack server. So, in a way, the development setup is closer to our envisaged CDN-based setup, with webpack acting as that third-party file host.
Take a look at the branch and think about how you might modify things to use a CDN for production. Note that the render-gateway code is currently specific to Google App Engine.
Some final SSR thoughts
Server-side rendering is great for providing search engines with a more complete version of your page when they come crawling your site. It is also great at showing more of your page to your users on first display. And if used unnecessarily, it is a great way to sloooooooow the delivery of your site 😱.
If you always SSR a page before serving it to users, you could wait quite a while for that page to finally land in front of the user. The real value of SSR is only realised when it is coupled with caching so that an SSR result can be re-used for multiple requests. This can be easy to setup with a service like CloudFlare or Fastly, but to do it right and get the best cache hits without compromising your users data or the utility of your site can take a little more work. You will want to familiarise yourself with things like the Vary response header, edge-side includes, and other useful concepts. Not to mention performance and other site metrics so that you can measure the impact of your SSR strategy and make sure it is serving its purpose without hindering your site or your users.
Whatever you choose to do next, I hope this series on server-side rendering with React has demystified the topic and provided you with some helpful resources as you consider SSR and what it may mean to your current or next project – please stop by and let me know about your SSR adventures in the comments. In the meantime, as the React team works more on React and features like Suspense, the server-side rendering story, like so many software developments stories, is going to change.
For now, thank you for joining me on this SSR journey. When I started, I thought I knew everything I needed to know about SSR in order to tell you everything you needed to know about it. It should come as no surprise to any of us that I still have things to learn.
- The pandemic that showed up right after we started also contributed to the complexity of the project as more and more folks around the world turned to us to support their education [↩]
- The
Varyresponse header allows a server to tell a cache like the one Fastly provides with headers in the request were used to generate that response. Along with the URL and other considerations, this tells the cache what header values need to match for a cached page to be used versus requesting a new response from our server [↩] - At the time of writing, that issue is still open although there is ongoing movement to suggest it may soon be resolved, or made redundant with the removal of that feature from Google's offering [↩]
- There are currently no NPM packages to install for this, though I hope to change that – instead, the
distis included in the repo and we install via commit SHA [↩]