
I have spent the first couple of months of 2017 learning about the new features in C#7. This would not have been possible without some tools to help me play around with the new language syntax and associated types. Since we have to wait a little longer until Visual Studio 2017 is released, I thought you might like to know what tools I have been using to tinker in all things C#7.
LINQPad Beta
Link: http://www.linqpad.net/Download.aspx#beta
While early releases of Visual Studio 2017 (scheduled for release on March 7th) support the language, I initially found the release candidate to be unstable and frustrating. Not only that, but it can be cumbersome to spin up a quick example using Visual Studio, so I turned to my trusty friend, LINQPad.
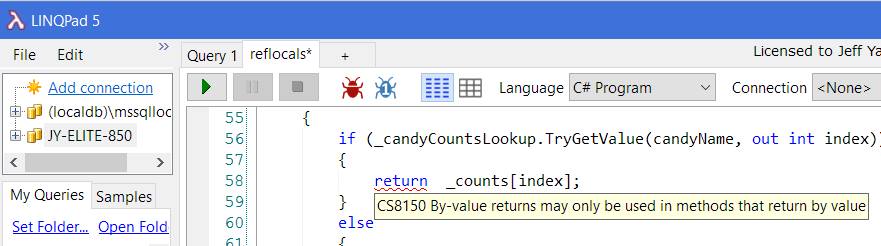
I cannot recommend LINQPad enough, it is a fantastic tool for prototyping, poking around data sources, and more besides, like tinkering with language features you don't yet understand. While LINQPad's current release only supports the C# language up to version 61, the beta release also supports C# version 7. Not only can you use the language, but with the fantastic analysis window, you can see how Roslyn breaks down each part of the code. If you want to get started quickly, easily play around with the cool new features, and have a powerful tool for digging deeper as the need arises, the LINQPad beta is the tool to get.
Visual Studio 2017 RC
Link: https://www.visualstudio.com/downloads/

Yes, I know I said it was unstable and frustrating, but that was before, way back in January. These days the RC is much, much better and with the release date set for March 7th, there was never a better time to install Visual Studio 2017 RC and get a head start on getting to know some of the new things it can do, including C# 7. Tuples are fun, but poking around with them in the debugger is funner.
OzCode
Link: https://oz-code.com/
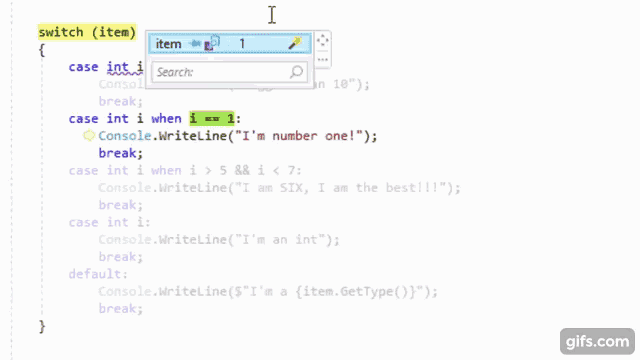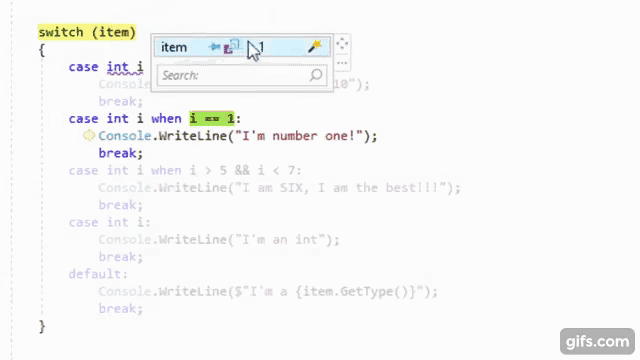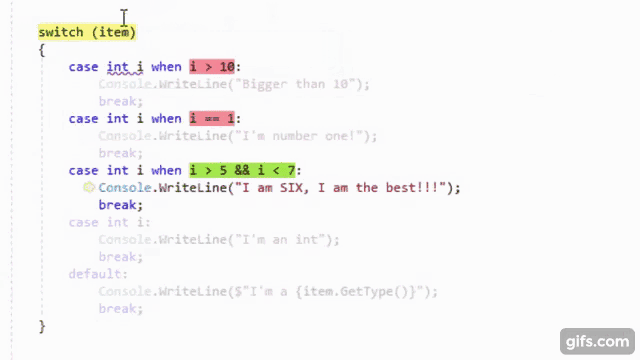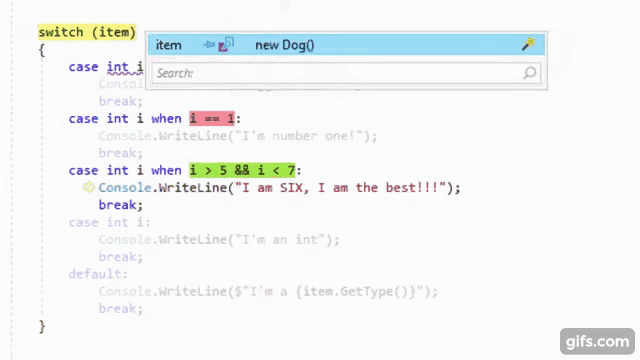
It is no secret that I love OzCode, the magical debugging extension for Visual Studio. It is so well-known that they asked me to be part of their OzCode Magician community program. So, it should come as no surprise that I have been using OzCode in my exploration of C#7. As the Visual Studio 2017 RC has matured, the clever people over at CodeValue have been creating previews of OzCode version 3, including amazing LINQ debugging support. Recently, I got to try an internal build that included support for all the cool new things in C#7.
OzCode 3 will be released on March 7th, the same day as Visual Studio 2017.
Documentation
Link: https://docs.microsoft.com/dotnet/articles/csharp/csharp-7
Never underestimate the power of reading documentation, it is one of the best tools out there. For my C#7 posts, I relied heavily on the new docs.microsoft.com site, specifically the .NET articles on C#. Not only is this a fantastic resource, but it has built-in support for commenting on the documentation so that you can ask questions and contribute to their improvement.
In Conclusion
This is the entire list of tools I used for my C#7 investigations. Try them out and get an early start on C#7 fun before the March 7th release of all the C#7 goodness. Happy tinkering and if you stumble on any useful tools, please share in the comments!
- It also supports SQL, F#, and VB [↩]




 After a dismissing using git locally to perform this task (I figured those who might need this tool would probably not want to get the repository locally) and reading up on the
After a dismissing using git locally to perform this task (I figured those who might need this tool would probably not want to get the repository locally) and reading up on the